Use case
Agentic reasoning & trajectories
Build the next generation of AI agents and solve the training bottleneck with scalable, human-based trajectory training and evaluation

Why Labelbox for agentic reasoning

Generate high-quality data
Empower human experts to easily refine existing trajectories or create new, ideal examples, ensuring the best possible training data for your models.

Scale agent development
Use the purpose-built Agent Trajectory Editor to efficiently manage the data lifecycle for agentic systems, and scale up human evaluations with Alignerr.

Accelerate development
Streamline the creation, annotation, and analysis of agent trajectories, significantly reducing the time from initial concept to deployment.

Custom evaluation workflows
Use customizable, fine-grained tools to pinpoint exactly where agents are succeeding and failing, leading to more effective training and optimization.
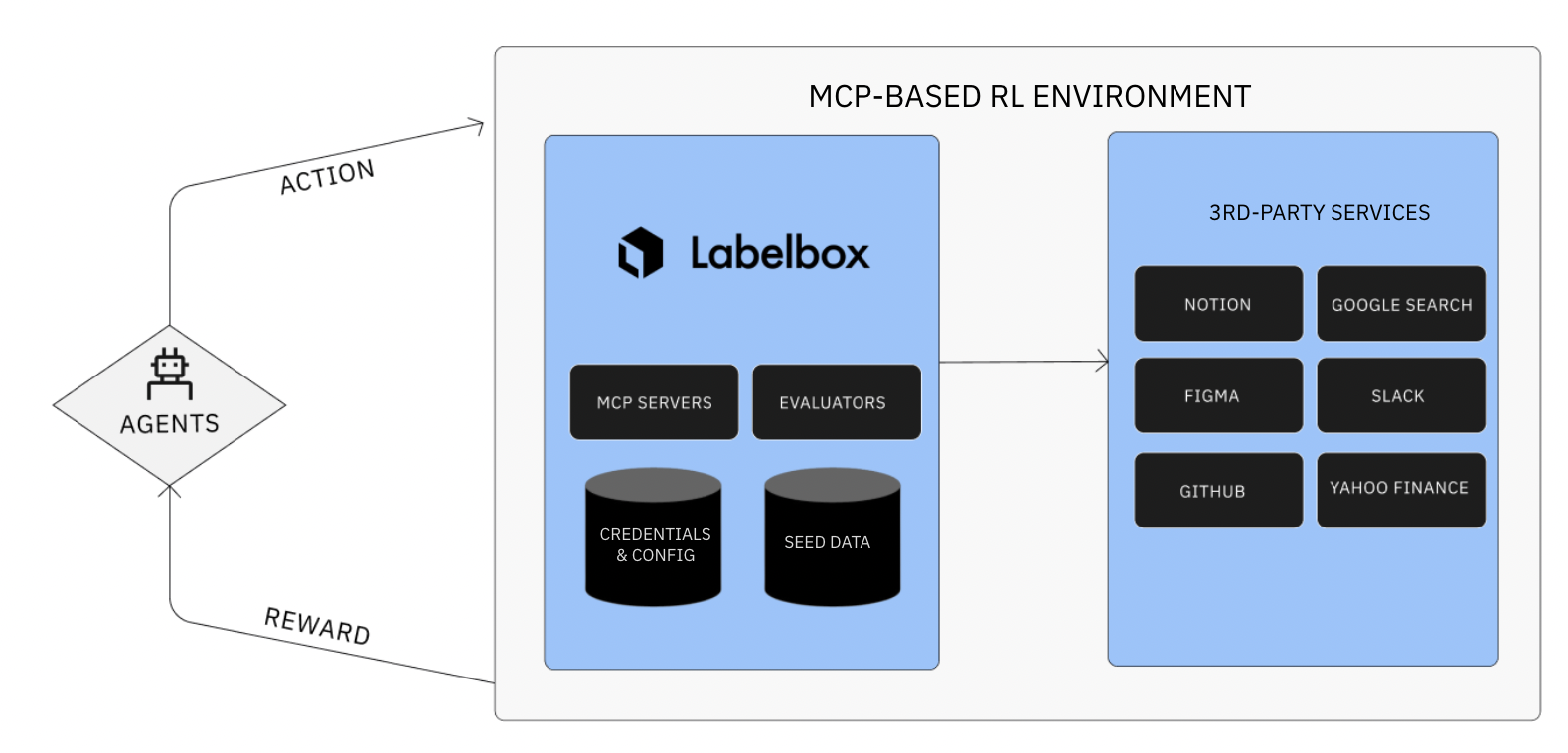
Realistic RL environments via MCP
Labelbox lets AI labs evaluate agents in real-world RL environments using live integrations with services like Slack, GitHub, Figma, Notion, and Google Workspace. Unlike simulated environments, these integrations expose agents to real APIs, edge cases, and data inconsistencies, testing not just scripted steps but their ability to navigate messy, unpredictable systems. The result: richer, more reliable signals of real-world performance.
Critical tasks needed to enhance agentic reasoning & trajectories

Analyze source quality
Assess if the agent used reliable and appropriate sources for information retrieval.

Detect biases & fairness
Identify any biases or unfair representations present in the agent's trajectory or final output.

Evaluate optimal tool use
Determine if the agent selected the most effective tools and used them correctly to achieve its goals.

Review reasoning logic
Evaluate the soundness and efficiency of the agent's planning and reasoning steps.

Enhance output formatting
Ensure the agent's output conforms to desired style, structure, and branding guidelines.

Validate full task completion
Evaluate the final task completion status to ensure the agent fulfilled the original goal.
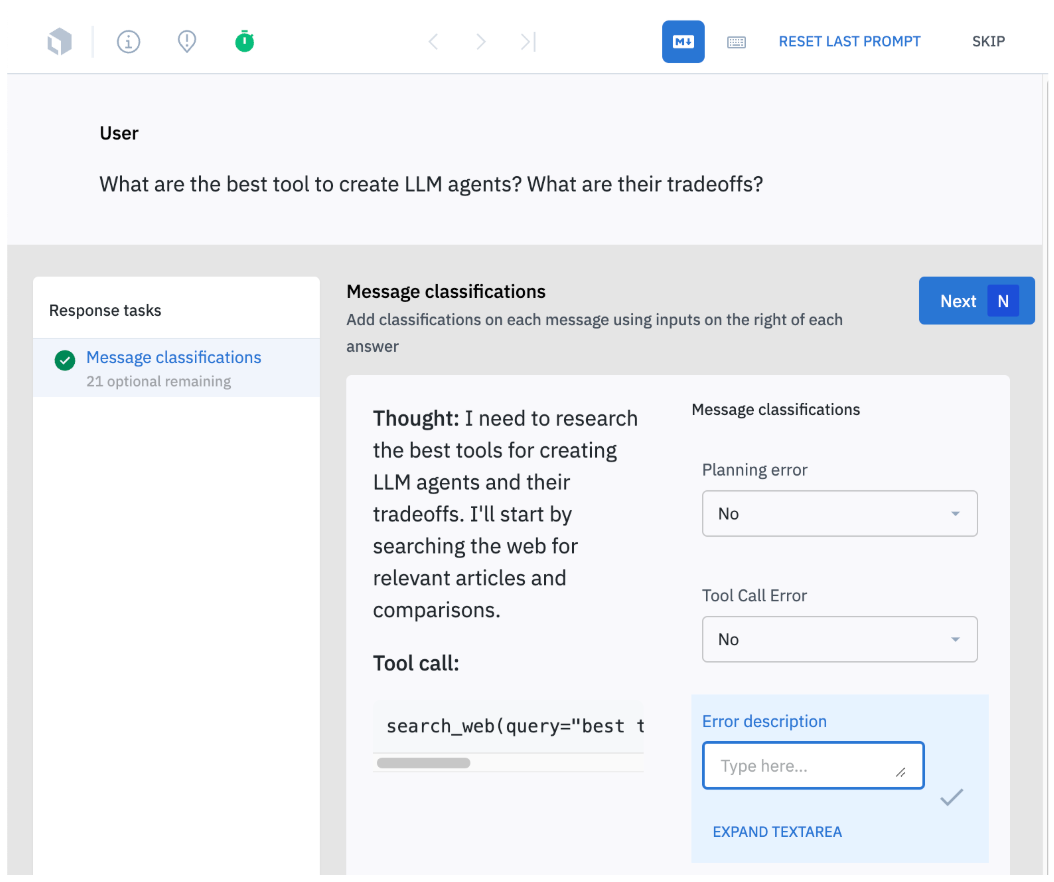
The hurdles in evaluating and training agentic systems
Evaluating and training AI agents is challenging. Trajectory data is complex, requiring specialized tools for capture and annotation.
Planning Error: Did the agent make a mistake in deciding what to do next? Labelbox helps teams detect these reasoning errors by comparing the agent’s intended plan against ground-truth outcomes, revealing where logic or strategy breaks down.
Tool Call Error: Did the agent use the right tool with the correct inputs? Labelbox identifies and labels tool usage failures, helping teams trace whether errors stem from the model’s reasoning or from execution issues in external tools.
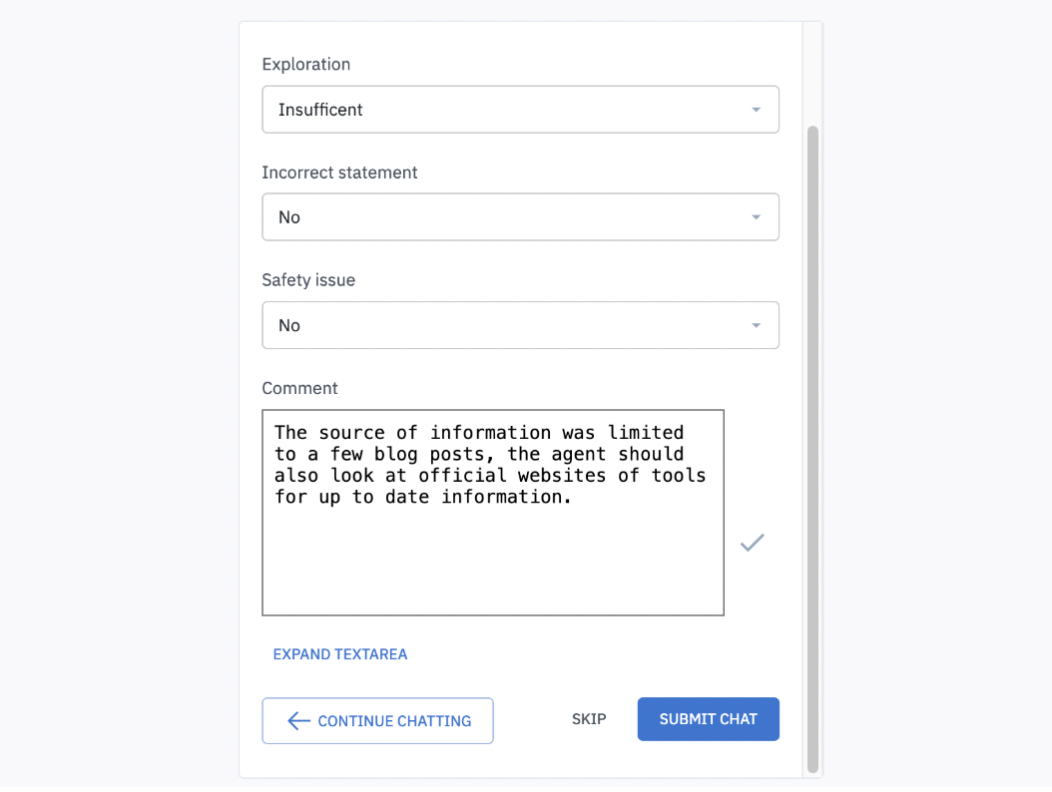
Accelerate agentic AI development with Labelbox
Labelbox's Agent Trajectory Editor simplifies agent training and evaluation. We make it easy to evaluate research agents by capturing key signals like Exploration (did it search broadly enough?), Accuracy (are any facts wrong?), and Safety (is any content biased or unsafe?)—so teams can quickly see where the model falls short and how to improve it.
Tap into the Alignerr Network, operated by Labelbox, to hire skilled AI trainers for model evals, data generation, and labeling
Customer spotlight
In partnership with a leading frontier AI lab, we generated a series of complex reasoning data for everyday domains, such as planning and scheduling, calendar optimization, travel booking, and restaurant staff scheduling. By supporting the labs post-training activities with high-quality data, we accelerated their voice assistant's natural planning capabilities.
Learn more >

